Machine Learning, phân loại - Một cách dễ hiểu nhất (Bài viết mở đầu)
Mục lục
- 1. Giới thiệu
- 2. So sánh giữa máy móc và con người
- 3. Machine Learning là gì?
- 4. Phân loại Machine Learning
- 5. Phân loại Machine Learning
- 6. Tham khảo
- Bình luận & thảo luận
1. Giới thiệu
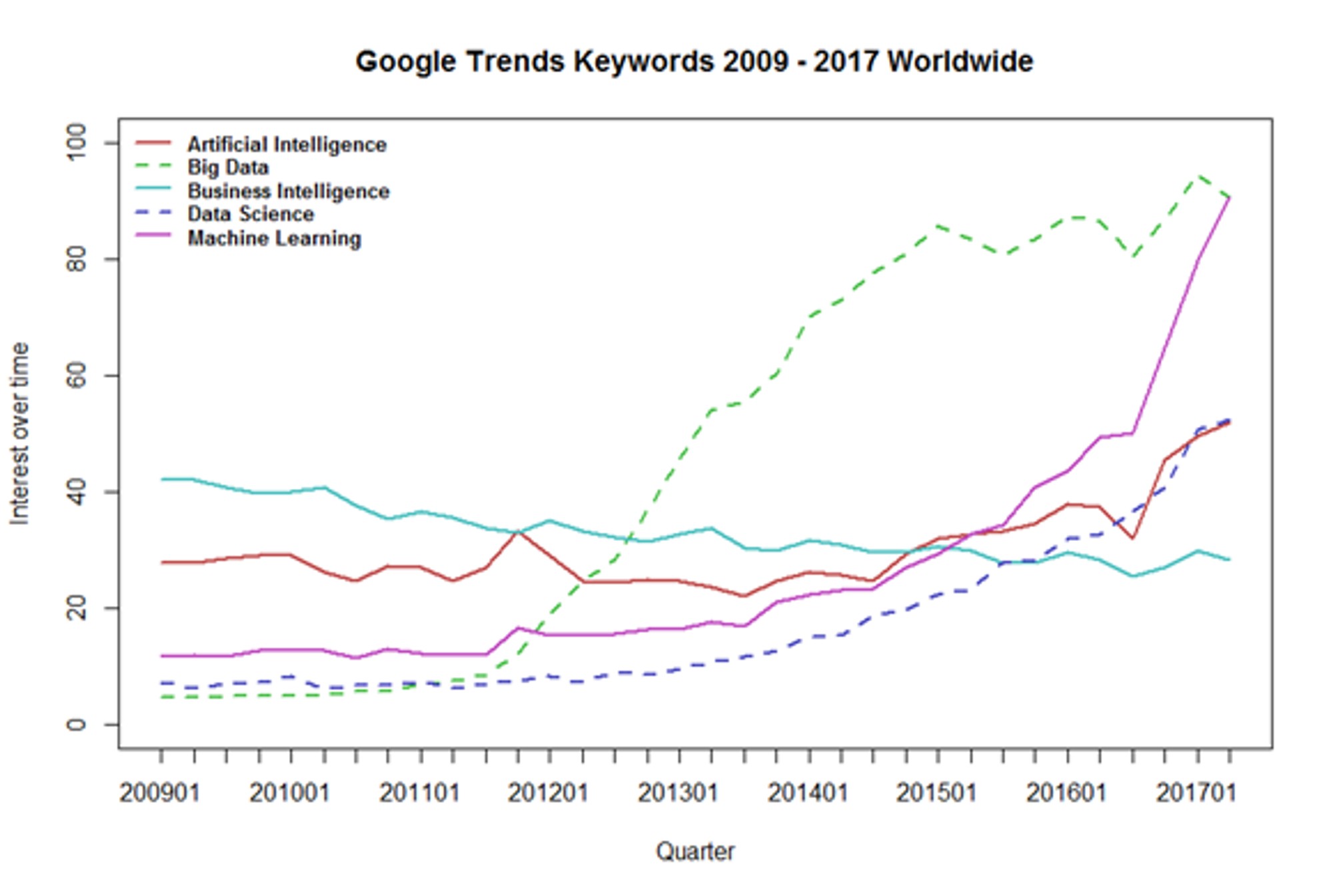
Trí tuệ nhân tạo (AI), học máy (Machine Learning), học sâu (Deep Learning) là những từ nóng nhất hiện nay, chúng ta có thể thấy sự phát triển nhanh chóng thông qua biểu đồ dưới, vậy Machine Learning là gì?, hãy cùng tìm hiểu trong bài hôm nay.
2. So sánh giữa máy móc và con người
Đầu tiên chúng ta hãy so sánh giữa máy móc và con người, một sự khác biệt quan trọng giữa con người và máy tính là khả năng học hỏi từ những kinh nghiệm trong quá khứ. Con người có khả năng rút ra bài học từ kinh nghiệm đã trải qua. Trái lại, máy tính hoặc máy móc cần được hướng dẫn rõ ràng về cách thực hiện một nhiệm vụ cụ thể. Máy tính là những thiết bị logic mà không có khả năng tự nhìn nhận và hiểu được ý nghĩa thông thường như con người.
Điều đó ngụ ý rằng nếu chúng ta muốn máy tính hoặc máy móc thực hiện một nhiệm vụ cụ thể, chúng ta cần cung cấp cho chúng hướng dẫn chi tiết, từng bước, về những công việc cần thực hiện một cách chính xác.
Ví dụ về việc cung cấp hướng dẫn chi tiết cho máy tính là khi chúng ta lập trình một chương trình đơn giản để tính tổng của hai số. Chúng ta cần chỉ rõ cho máy tính các bước cụ thể để thực hiện công việc này, bao gồm:
- B1: Nhập số thứ nhất từ người dùng.
- B2: Nhập số thứ hai từ người dùng.
- B3: Thực hiện phép cộng của hai số này.
- B4: Hiển thị kết quả tổng lên màn hình.
Trong ví dụ này, chúng ta phải cung cấp cho máy tính các hướng dẫn cụ thể về việc nhập dữ liệu, thực hiện phép toán và hiển thị kết quả. Máy tính không thể tự nhận biết và thực hiện các bước này mà cần sự chỉ dẫn rõ ràng từ chúng ta.
Nó giống như việc mình viết kịch bản (bằng ngôn ngữ lập trình) để cho máy tính làm theo vậy, Đó là lý do mà Machine Learning (học máy) ra đời. nó giúp máy tính học hỏi từ dữ liệu kinh nghiệm trong quá khứ.
Thế giới ngày càng chứa đầy dữ liệu. Rất nhiều và rất nhiều dữ liệu. Mọi thứ từ hình ảnh, âm nhạc, từ ngữ, bảng tính, video và hơn thế nữa. Và điều đó làm cho machine learning ngày càng phát triển
Lúc đầu, Machine Learning có vẻ giống như phép thuật, nhưng khi bạn tìm hiểu kỹ, bạn sẽ thấy rằng đó là một bộ công cụ để rút ra ý nghĩa từ dữ liệu.
3. Machine Learning là gì?
Người ta nói rằng Machine Learning giống như một chiếc rương báu đầy bí mật, đầy hấp dẫn nhưng cũng không kém phần thử thách. Vì vậy, nếu bạn đào quá sâu, bạn sẽ bị lạc trong những đường hầm hỗn loạn của Machine Learning, giống như cách những sợi tóc đầy màu sắc trên đầu bạn quấn quýt lẫn nhau. Nhưng đừng lo lắng, nếu bạn có niềm đam mê với nó, hãy chuẩn bị tinh thần và cùng chúng tôi khám phá những bí mật của Machine Learning và đừng quên mang theo bộ đào và mũ bảo hiểm…
Có rất nhiều định nghĩa về machine Learning, Một định nghĩa phổ biến về ML được Tom Mitchell cung cấp như sau: A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.
Diễn giải: Machine Learning là một chương trình máy tính được gọi là học từ kinh nghiệm (Dữ liệu) E với tác vụ (dự đoán, phân lớp, gom nhóm) T và được đánh giá bởi độ đo (độ chính xác) P nếu máy tính khiến tác vụ T này cải thiện được độ chính xác P thông qua dữ liệu E cho trước*
Rất khó hiểu đúng không, để tôi giải thích bằng ngôn ngữ đơn giản cho bạn nghe:
Machine Learning là một lĩnh vực của trí tuệ nhân tạo (AI) nghiên cứu cách để máy tính tự động học hỏi và cải thiện từ dữ liệu và kinh nghiệm trước đó mà không cần được lập trình cụ thể.
Cụ thể: Quá trình học của máy tính bắt đầu bằng việc quan sát và thu thập dữ liệu từ ví dụ, trải nghiệm trực tiếp hoặc thông qua hướng dẫn. Máy tính sẽ tìm kiếm các mẫu trong dữ liệu đó và sử dụng chúng để đưa ra các quyết định tốt hơn trong tương lai. Mục tiêu chính của quá trình này là cho phép máy tính học tự động mà không cần sự can thiệp hoặc trợ giúp từ con người, và điều chỉnh hành động của nó để phù hợp với các tình huống.
Ví dụ:
Một cái ví dụ đơn giản nhất về Machine Learning mà mình có thể tìm thấy đó là dự đoán cân nặng của một người dựa trên chiều cao của họ.
Chúng ta có một tập dữ liệu gồm các thông tin về chiều cao và cân nặng của nhiều người. Sử dụng linear regression (một thuật toán của Machine Learning) , chúng ta có thể huấn luyện một mô hình dự đoán cân nặng dựa trên chiều cao.
Mô hình linear regression sẽ tìm ra một đường thẳng tốt nhất để phù hợp với dữ liệu
Sau khi mô hình đã được huấn luyện, chúng ta có thể sử dụng nó để dự đoán cân nặng của một người mới dựa trên chiều cao của họ. Mô hình sẽ áp dụng đường thẳng đã học được để tính toán cân nặng dự kiến.
Ví dụ, nếu chúng ta có thông tin về một người có chiều cao là 170cm, chúng ta có thể sử dụng mô hình để dự đoán cân nặng dự kiến của người này.
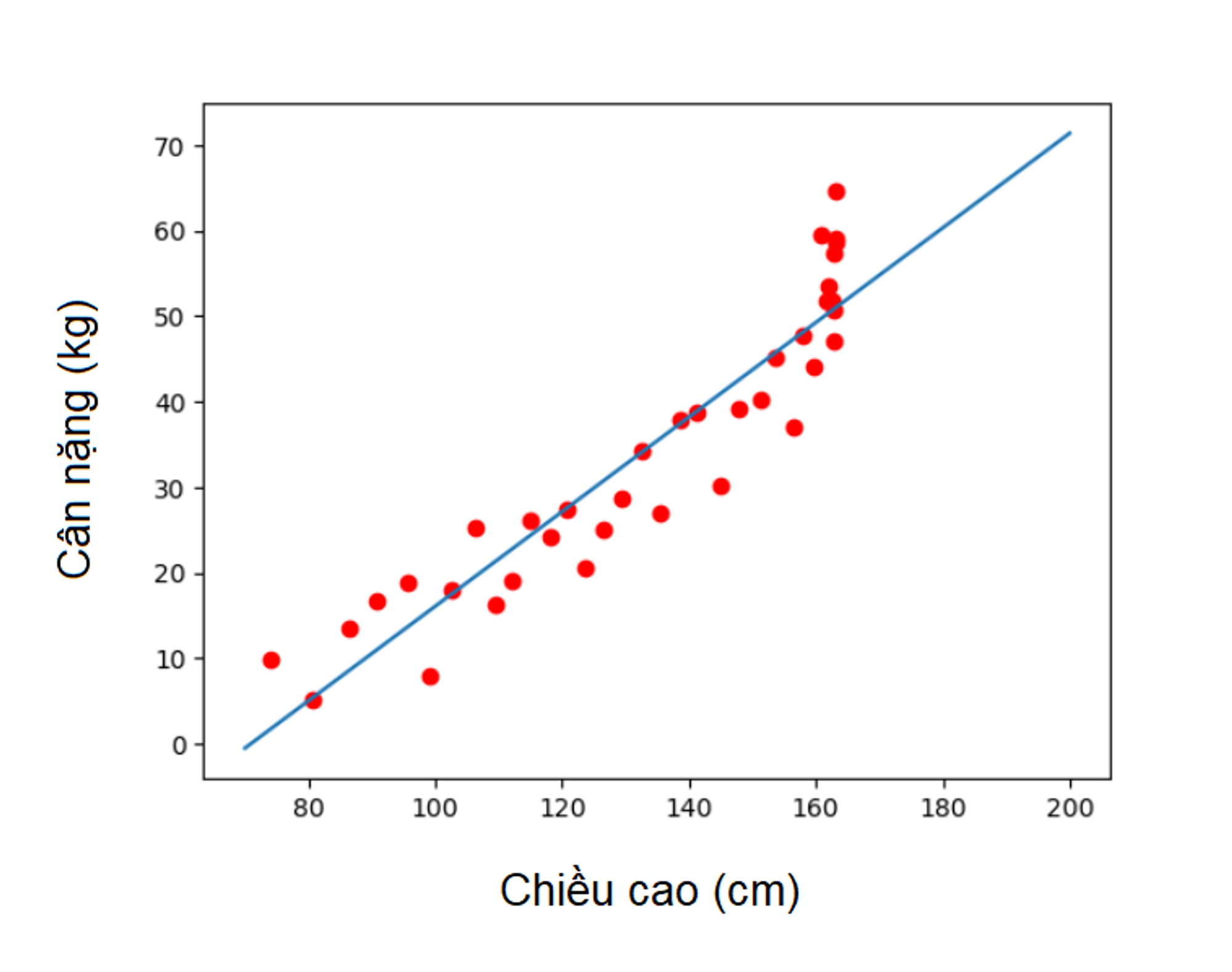 Linear Regression một ví dụ đơn giản về Machine learning.
Linear Regression một ví dụ đơn giản về Machine learning.
4. Phân loại Machine Learning
Có khá nhiều cách để phân loại Machine Learning, dựa vào phương pháp học của mỗi thuật toán hoặc là dựa trên chức năng như 2 hình dưới đây:
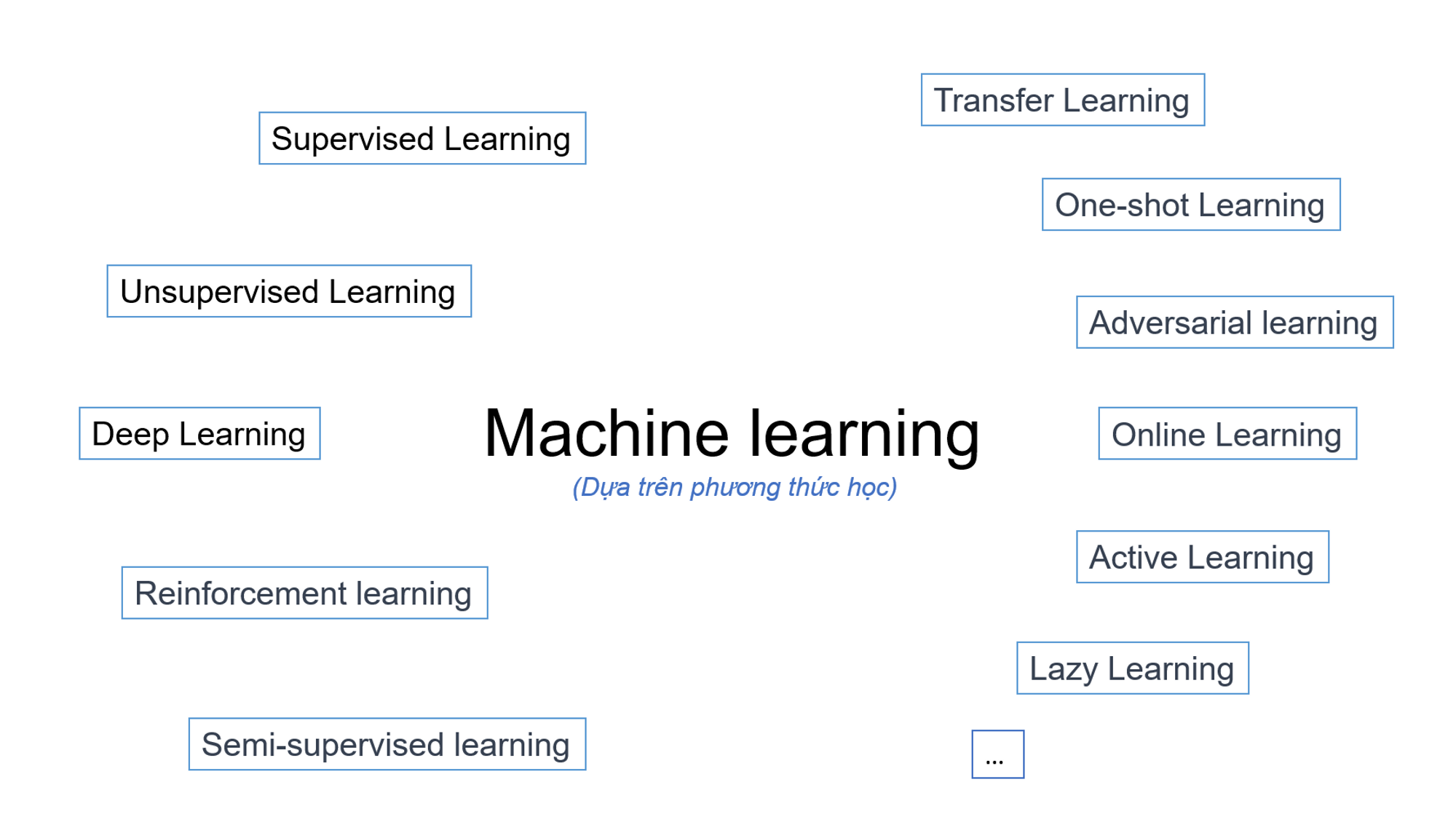 Phân loại theo cách học
Phân loại theo cách học
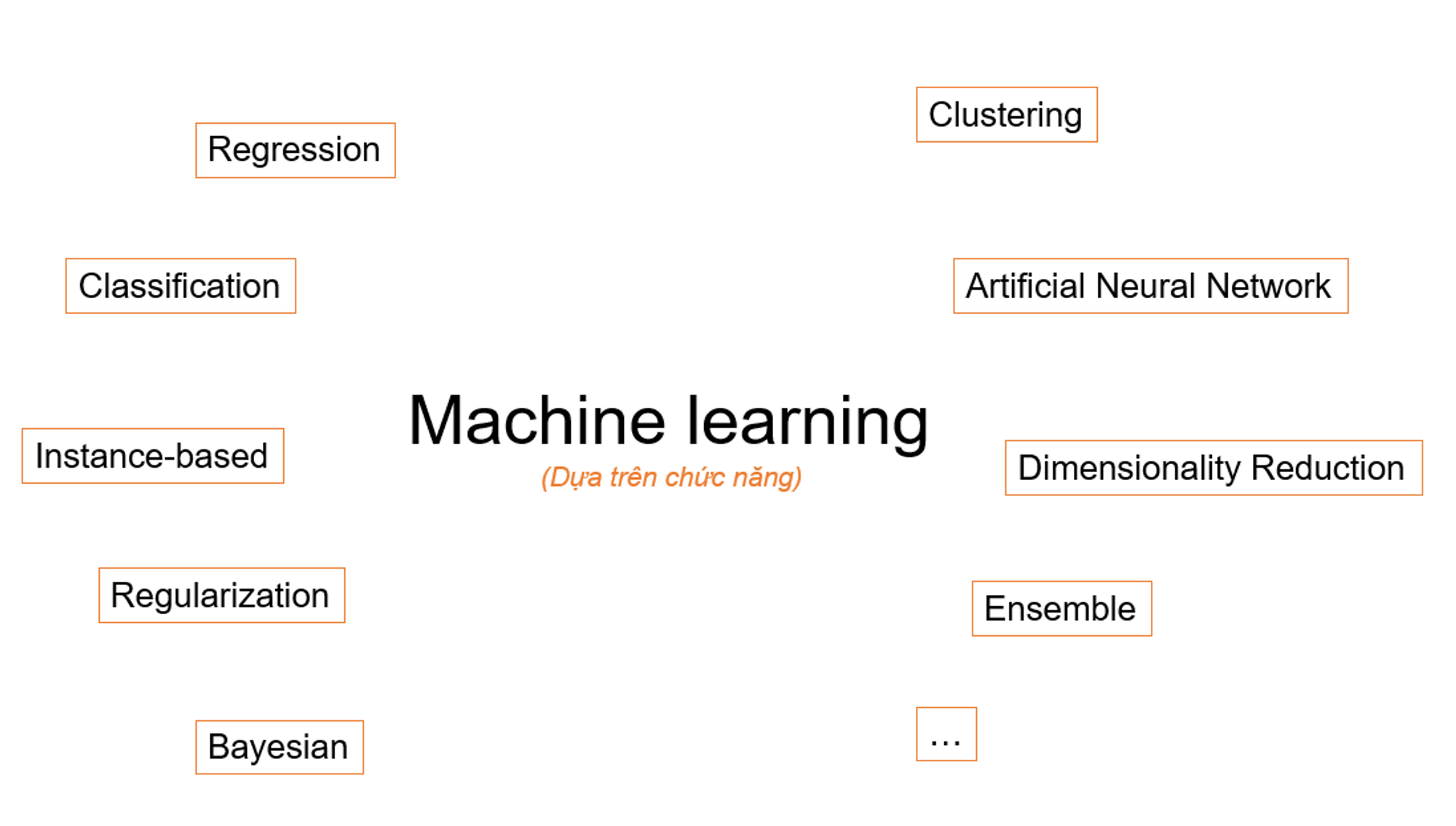 Phân loại theo công dụng
Phân loại theo công dụng
Nhưng bình thường phổ biến và đơn giản hơn cả thì các thuật toán học máy thường được phân loại là có giám sát (supervised learning) hoặc không giám sát (unsupervised learning).
4.1 Dựa trên Learning style (phương thức học)
Chúng ta có rất nhiều phân loại nếu bạn tìm hiểu sâu vào machine learning, nhưng trong bài viết này chúng ta sẽ tìm hiểu những loại cơ bản và phổ biến nhẩ
a. Supervised Learning (Học có giám sát)
Là thuật toán dự đoán đầu ra (outcome) của một dữ liệu mới (new input) dựa trên các cặp (input, outcome) đã biết từ trước, cặp dữ liệu này còn được gọi là (data, label: nhãn) và là phổ biến nhất trong các thuật toán Machine learning
Ví dụ: trong nhận dạng chữ viết tay, ta có ảnh của hàng nghìn ví dụ của mỗi chữ số được viết bởi nhiều người khác nhau. Chúng ta đưa các bức ảnh này vào trong một thuật toán và chỉ cho nó biết mỗi bức ảnh tương ứng với chữ số nào. Sau khi thuật toán tạo ra một mô hình, tức một hàm số mà đầu vào là một bức ảnh và đầu ra là một chữ số, khi nhận được một bức ảnh mới mà mô hình chưa nhìn thấy bao giờ, nó sẽ dự đoán bức ảnh đó chứa chữ số nào.
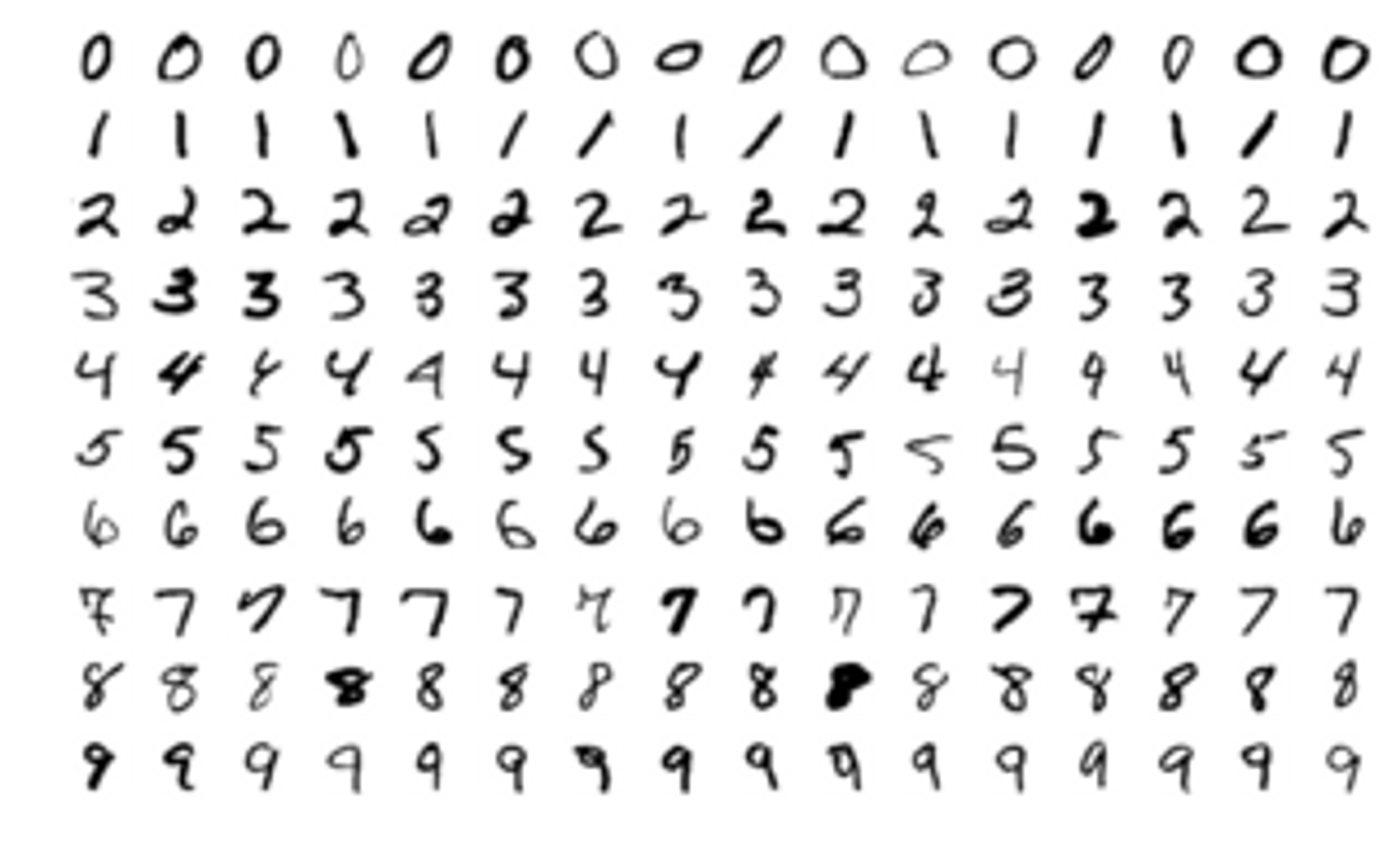 MNIST: bộ cơ sở dữ liệu của chữ số viết tay
MNIST: bộ cơ sở dữ liệu của chữ số viết tay
Ví dụ này khá giống với cách học của con người khi còn nhỏ. Ta đưa bảng chữ cái cho một đứa trẻ và chỉ cho chúng đây là chữ A, đây là chữ B. Sau một vài lần được dạy thì trẻ có thể nhận biết được đâu là chữ A, đâu là chữ B trong một cuốn sách mà chúng chưa nhìn thấy bao giờ.
b. Unsupervised Learning (Học không giám sát)
Trong thuật toán này chúng ta không biết được outcome hay nhãn mà chỉ có dữ liệu đầu vào. Thuật toán này sẽ dựa vào cấu trúc dữ liệu, thuật toán để thực hiện một công việc nào đó, ví dụ phân nhóm hoặc giảm số chiều của dữ liệu
c. Semi - Supervised Learning (Học bán giám sát)
Là các bài toán khi chúng ta có một lượng dữ liệu X nhưng chỉ một phần trong số chúng được gán nhãn
Một ví dụ điển hình là chỉ có một phần ảnh hoặc văn bản được gán nhãn và lại là các dữ liệu chưa gán nhãn thu thập thừ Internet.
d. Reinforcement Learning (Học củng cố)
Là các bài toán giúp cho một hệ thống tự động xác định hành vi dựa trên hoàn cảnh để đạt lợi ích cao nhất, hiện tại Reinforcement learning chủ yếu được áp dụng vào lý thuyết trò chơi
Vd: Alphago chơi cờ vây
4.2 Dựa trên công dụng
a. Classification Algorithms (Thuật toán Phân loại)
Một bài toán được gọi là classification nếu các label của input data được chia thành một số hữu hạn nhóm. Ví dụ: Gmail xác định xem một email có phải là spam hay không; các hãng tín dụng xác định xem một khách hàng có khả năng thanh toán nợ hay không. Hai ví dụ phía trên được chia vào loại này.
b. Regression Algorithms (Thuật toán Hồi quy)
Nếu label không được chia thành các nhóm mà là một giá trị thực cụ thể. Ví dụ: một căn nhà rộng x m2, có y phòng ngủ và cách trung tâm thành phố z km sẽ có giá là bao nhiêu?
Gần đây Microsoft có một ứng dụng dự đoán giới tính và tuổi dựa trên khuôn mặt. Phần dự đoán giới tính có thể coi là thuật toán Classification, phần dự đoán tuổi có thể coi là thuật toán Regression. Chú ý rằng phần dự đoán tuổi cũng có thể coi là Classification nếu ta coi tuổi là một số nguyên dương không lớn hơn 150, chúng ta sẽ có 150 class (lớp) khác nhau.
c. Clustering Algorithms
Thuật toán phân cụm (Clustering Algorithms) là các phương pháp trong học máy không giám sát (unsupervised learning), được sử dụng để tạo ra các nhóm (clusters) từ dữ liệu mà không cần thông tin nhãn (label) trước. Mục tiêu của phân cụm là nhóm các điểm dữ liệu có tính chất tương tự lại với nhau trong cùng một cluster, trong khi các điểm dữ liệu trong các cluster khác nhau có tính chất khác biệt.
d. Instance-based Algorithms
Instance-based Algorithms (còn gọi là Lazy Learning) là một loại thuật toán học máy không giám sát, trong đó mô hình không được xây dựng trong quá trình huấn luyện. Thay vào đó, mô hình lưu trữ toàn bộ dữ liệu huấn luyện và sử dụng dữ liệu này trực tiếp để đưa ra dự đoán cho các điểm dữ liệu mới. Instance-based Algorithms giữ nguyên các điểm dữ liệu trong tập huấn luyện để sử dụng làm thông tin khi dự đoán.
e. Bayesian Algorithms
Các thuật toán Bayesian là nhóm các phương pháp và kỹ thuật trong thống kê và máy học dựa trên lý thuyết xác suất Bayes. Điểm chính của các thuật toán này là chúng sử dụng thông tin xác suất để làm dự đoán và cập nhật dự đoán khi có thêm thông tin mới. Các thuật toán Bayesian đưa ra dự đoán dựa trên sự kết hợp giữa kiến thức tiền đề (prior knowledge)(kiến thức trước đó) và dữ liệu thực tế (evidence).
Vì khó hình dung nên mình sẽ đưa ra một ví dụ đơn giản về Bayesian là khi chơi thử một trò chơi bắn bi, trong đó mục tiêu nằm trong một vùng chưa xác định trên một bức tường. Ban đầu, bạn có kiến thức tiền đề rằng mục tiêu có thể xuất hiện ở bất kỳ vị trí nào trên bức tường, do đó, xác suất của mỗi vị trí là như nhau (prior). Sau mỗi lần bắn, bạn ghi nhận kết quả (evidence), ví dụ: trúng mục tiêu hay không. Dựa trên thông tin mới này, bạn cập nhật xác suất ứng với từng vị trí, và xác suất của mỗi vị trí sẽ thay đổi theo thời gian khi bạn có thêm dữ liệu.
5. Các thuật toán cơ bản cho mỗi phân loại trong Machine learning
Dưới đây là một sơ đồ cho bạn thấy được phân loại của machine learning một cách cơ bản nhất
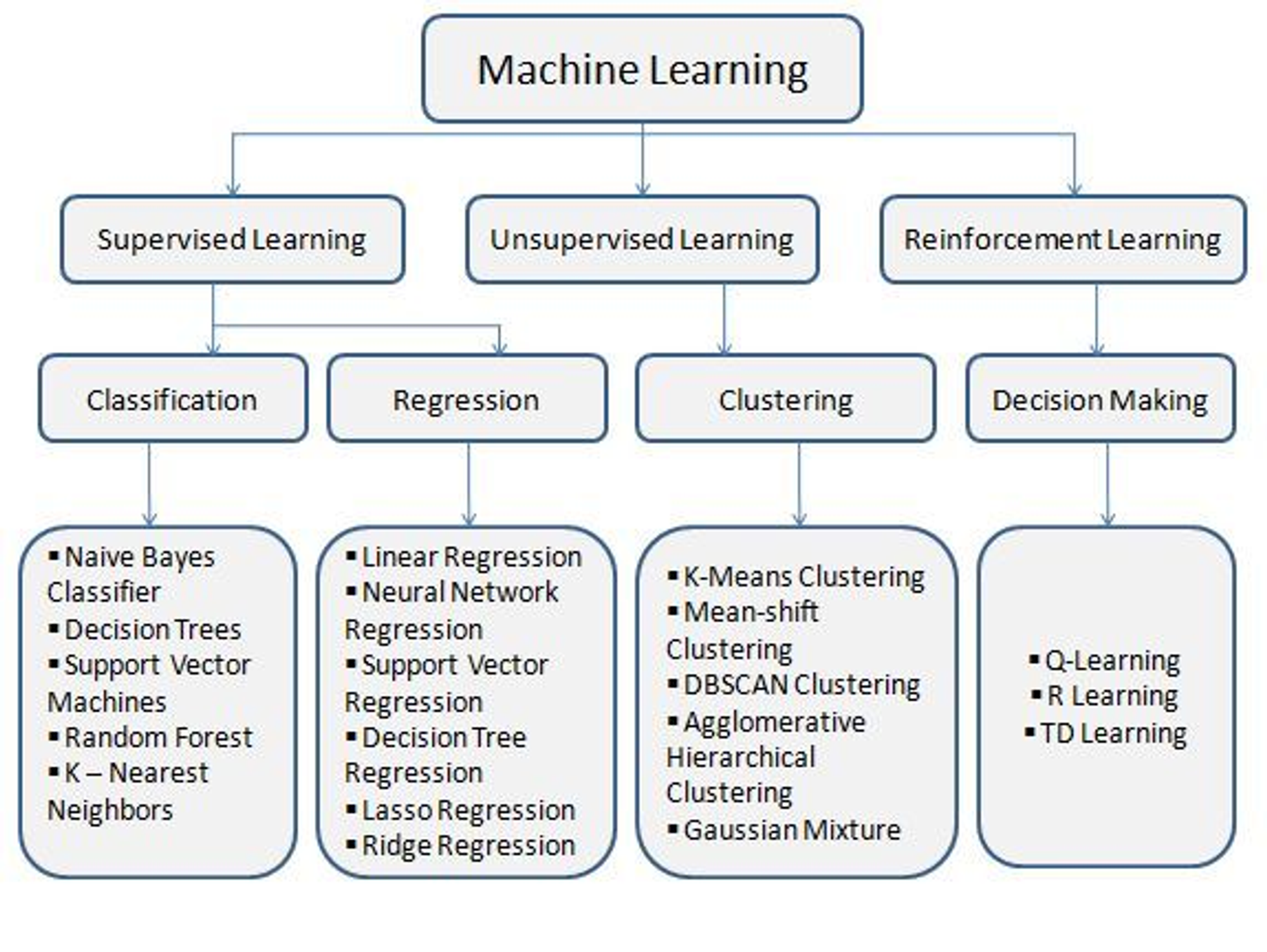 Hình ảnh phân loại cơ bản của Machine learning
Hình ảnh phân loại cơ bản của Machine learning
Bài viết vẫn đang update thêm…
6. Tham khảo:
[1] yannmjl.medium.com what-is-machine-learning-in-simple-english
[2] https://medium.com/swlh/what-exactly-is-machine-learning-50789d7860ec
[3] machinelearningcoban.com introduce
[4] machinelearningcoban.com categories
[5] https://www.datacareer.de/blog/is-data-science-still-on-the-rise-germany-answers-from-google-trends/
Bình luận & thảo luận
Cảm ơn bạn đã dành thời gian để đọc, hãy trò chuyện và góp ý với mình ở dưới hoặc vào bằng link .
Comments powered by Disqus.